A recent issue on the Gas Town repository alleges the platform quietly contributes upstream PRs using users' Claude credits and GitHub accounts, with no opt-in. This post argues the underlying mechanism is closer to a misconfigured feature than a bug, and that the same flow, made explicit and scoped, could become a useful default for open source contribution.
What follows is a sketch of what an opt-in token tithe could look like, what infrastructure would need to exist to support it, and why the cycle it creates might address problems that traditional sponsorship has not.
The idea
A few weeks ago an issue was opened on the Gas Town repository titled "Does Gas Town 'steal' usage from users' LLM credits & paid services to improve itself?". Gas Town is Steve Yegge's multi-agent workspace tool. The issue alleges that two formula files shipped with the default install cause local polecats (Gas Town's term for its work-doing agents) to pick up work from Gas Town's own upstream issues, running on the user's Claude credits and submitting PRs from the user's GitHub account. The formula files act as agent skills, telling the polecats when and how to contribute upstream. There was no README mention and no opt-in. Whether the formulas fire on a default install or only when the user triggers a release is contested in the thread, but the reporter documents multiple PRs that appear to have been triggered without explicit user intent. A third-party PR proposing an opt-in fix was closed by maintainers as out of scope for the current infrastructure-only intake. The issue itself was closed shortly after, with maintainers redirecting policy work to a separate project, and the behaviour in the default install stays in place.
This may be closer to a misconfigured feature than a bug. The flow is fine, it just needed to be opt-in. Flip it that way and the mechanism could work for open source in general, not just for an orchestration platform like Gas Town.
Given how good AI is becoming for everyday tasks, from writing emails to writing code, tokens start to look like currency. Given X tokens, you can trade them directly for the time and money it would take to do Y amount of work. Tokens are indirectly a unit of paid labor.
The token tithe
Open source has always struggled with maintenance. A voluntary, proportional, small share of compute given back to a project you depend on seems like a win-win by default. The user sets the cap, picks the scope, monitors the spend. A tithe is not a replacement for real sponsorship, but it runs on what users already spend, with no overhead of writing a cheque. You know exactly where your tokens go and the funding flow is fully transparent. Consent has to be explicit, scope has to be configurable, and attribution has to be clear enough that liability can be traced.
This is structurally different from sponsorship. Sponsors pay maintainers out of goodwill, sometimes without using the project themselves. With a tithe, the people funding the library are the same people using it, and the activity that created the dependency is the same activity that funds the work on it. The user benefits directly when the library improves.
The loop
A tithe that generates a flood of incoming PRs also generates a review problem, and at any serious volume review is itself a labor and token-heavy job. The same compute flow that funds the contribution could fund the review, with the tithe covering both sides. That turns into something closer to a circulating system: compute in, work done, work checked. The maintainer sees less manual load. That could prevent the library graveyard issue.
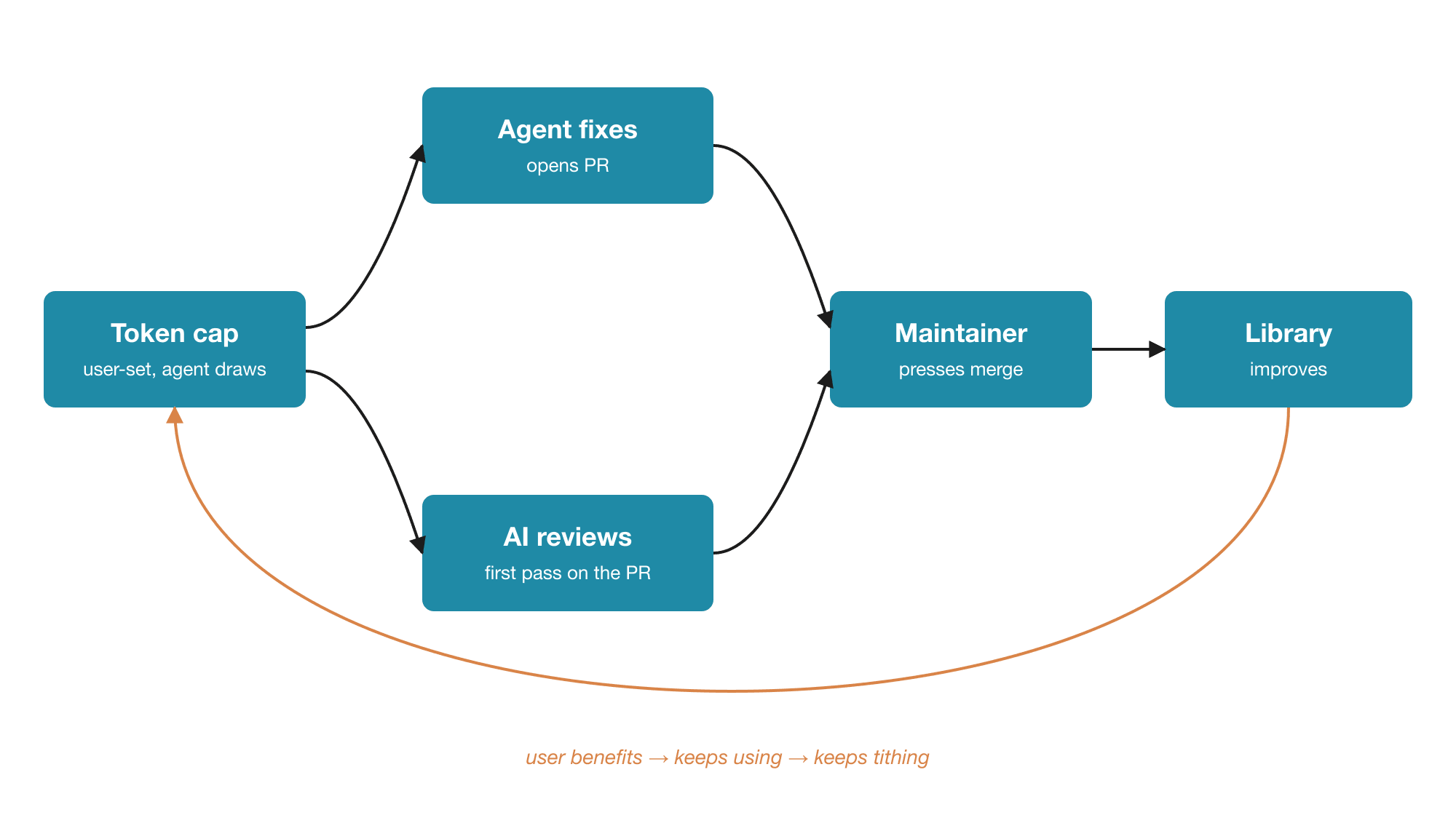
The tithe loop: the user closes the cycle by continuing to use and tithe
Everyone has encountered the following scenario at some point. You are using some package and it turns out it has not been updated in three years, the maintainer moved on, the open issues just pile up. Projects die because the amount of work grew past what one person can sustain on evenings and weekends. If tithed agents are doing the fixing and AI review is doing the first pass, the maintainer's remaining job is mostly to press merge, which is a different job entirely.
Tithing cannot save a fully abandoned project; the last mile still needs a human. But for projects with a maintainer who is just stretched thin, which is probably most of them, this is where it could actually add value.
There is a related failure mode the loop addresses, the maintainer-burnout cycle. A project becomes successful, the user count grows, the backlog scales proportionally while the maintainer's capacity stays fixed. Open source has many examples of overworked maintainers stepping back from their own creations, sometimes after years. This way the work continues without them having to be the bottleneck.
When projects don't want AI
Some projects do not want AI contributions and should not have to take any, but AI-assisted PRs are probably already arriving on most projects, with or without disclosure. A tithing flow at least makes that involvement explicit and traceable. The comparison is to the current state where AI involvement is invisible, not to an AI-free state that does not exist.
How it could work
The user-side piece is a single CLI tool, run inside each project. Call it tithe. You cd into a project, run tithe init, and it walks the directory for known dependency files: Podfile, Package.swift, package.json, Cargo.toml, requirements.txt, go.mod, Gemfile, pom.xml, build.gradle. Each format gets a per-package-manager parser. The per-project state lives in the project. Global user config (default cap, scope filters, AI tool of choice) lives at ~/.config/tithe/. GitHub authentication defers to gh or the git credential helper, so tithe never handles the token directly.
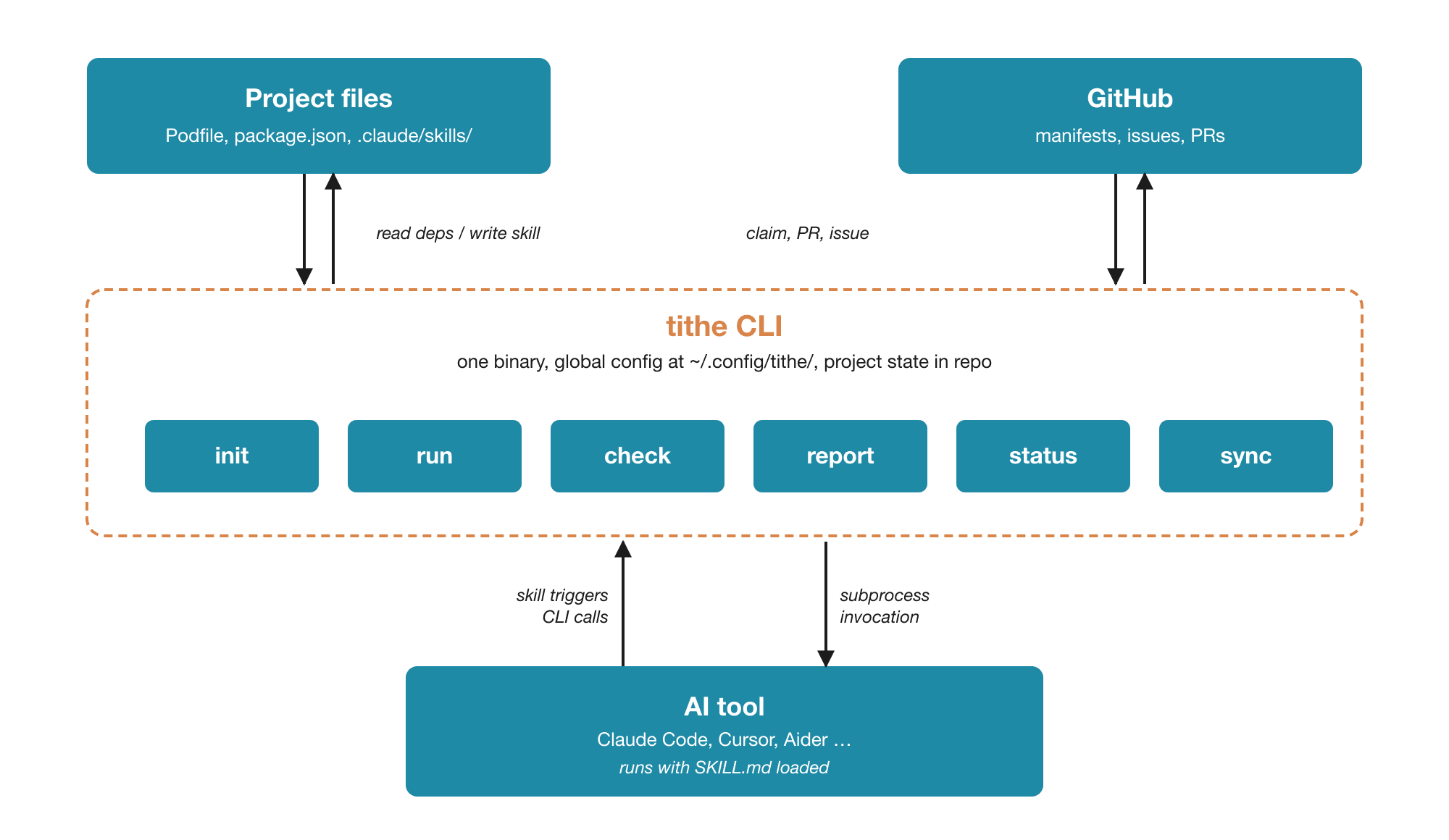
tithe CLI: one binary with subcommands sharing local state
The CLI is one binary with subcommands sharing state. tithe init scans the project's dependency files, resolves each package's source URL, and checks each repo for a .tithe.yml manifest. The dependencies that have one become this project's eligible-projects list, the subset you can actually tithe to. The same step installs the relevant skill template into the project. tithe run picks an issue from a manifest, posts a claim comment on GitHub to avoid duplicate work across users, invokes the user's AI tool as a subprocess to do the work, opens the PR with tithe attribution, and logs the session. tithe report files an issue against a tithed dependency on the agent's behalf, within the manifest's allowed scope and with the same attribution conventions. tithe status reads the local log and shows spend, open PRs, and merge state. tithe sync polls GitHub for merge state on tithe PRs and updates the log. There is also a tithe check <package> query, used by the skill layer below to ask whether a dependency is tithed before invoking anything else.
The dependency resolution step resolves package URLs. A Podfile says pod 'Alamofire' and to get the GitHub URL, the CLI looks up the pod's spec via the CocoaPods Trunk API (which redirects to the Specs repo) and reads the s.source field. Same shape for npm (registry -> repository.url), Cargo (crates.io API), Gemfile (RubyGems), pip (PyPI). Some are easier: Go modules use the import path as a lookup key that resolves directly to the repo for github.com/* paths and via meta-tag discovery for vanity domains, and Swift Package Manager has the URL in Package.swift directly. The shape is always: name in dependency file, registry lookup, source URL.
The cross-agent integration runs through a project-level skill or instruction file, which every serious AI tool already supports. For Claude Code that is a SKILL.md inside a directory under .claude/skills/; Cursor and other agents have their own equivalents. tithe init ships templates for each. The skill content is roughly: when the agent encounters a bug or unclear behaviour in a dependency during normal work, it runs tithe check on the package, and if eligible uses tithe report to file the issue and tithe run to attempt a fix. The same CLI works behind any agent because the trigger logic lives in the agent-specific skill, not in the CLI itself. Gas Town's formula files do exactly this, which is what makes the proposed architecture viable rather than speculative, the pattern is already deployed, just without the opt-in.
Manifest and config
On the maintainer side, the manifest declares what is in scope. A first sketch of .tithe.yml:
version: 1
issues:
labels: ["tithe-eligible", "good first issue"]
exclude_labels: ["wontfix", "design-needed"]
paths:
allowed: ["docs/", "tests/"]
forbidden: [".github/", "scripts/release/"]
branches:
pattern: "tithe/{user}/{issue}"
attribution:
pr_label: "tithe-contribution"
pr_body_marker: "Contributed via the tithe flow"
agents:
accept: ["*"]
On the user side, opt-in is once per project. After tithe init runs, the user picks which of the eligible dependencies to tithe to, sets a cap (a fixed monthly token budget or a percentage of total spend, so a heavy user contributes proportionally more), and picks scope filters such as docs-only, tests-only, or no schema changes. Enforcement reads token usage from the agent at each call boundary, so the cap is an approximate ceiling with overshoot bounded by a single LLM call, not an exact stop. When they run tithe run, the CLI picks within those constraints, invokes the AI tool, logs the session, and opens the PR. The user can pause, scope down, or revoke at any time, and they can review the picked queue before any work runs.
What needs to be built
The building blocks are there. AI tools run agents and track tokens, GitHub handles identity and labels, repo-level config is well established, and every serious agent has a skill or instruction format that can carry the trigger logic. What does not exist yet is a tithe layer on top: the manifest format, the orchestration to read it, a way to attribute spend to specific contributions, conventions for PR labelling, a claim mechanism for parallel users on the same issue, and skill templates targeting each major agent.
Conclusion
Can it become a thing? Probably, the infrastructure is mostly there and the incentives line up. Users would support libraries they actually depend on without having to write a cheque, maintainers would spend less time on routine work, and projects would keep moving when they would otherwise stall.
Should it? Given the scale of compute flowing through these tools, given how little has historically flowed back to the projects that make them possible, should a proportional opt-in token tithe become a normal part of using open source?




