Vision language models can describe images in remarkable detail, but when you ask them to tell you exactly where something is in a photo, the results fall apart. This post explores why VLMs fail at spatial localization, what the research says about it, and what we learned firsthand while building an on-device computer vision feature.
We compare VLM outputs against dedicated object detection models like YOLO, show the results with real images, and explain why composite pipelines that combine both tools are the most practical path forward.
The problem
Say you're building a traffic monitoring feature where a camera captures a busy intersection and your app needs to highlight every vehicle in the frame so the system can count traffic, classify vehicle types, or flag violations. The app doesn't just need to know that there are cars in the photo, it needs to know precisely where each one starts and ends, down to the pixel, so it can draw rectangles around them and tie each region to a database record.
With AI as capable as it is in 2026, this feels like it should be straightforward. You could send the image to Claude or GPT-4o, ask it to return bounding box coordinates, and wire up the results. These models can describe a street scene in remarkable detail, they'll read a license plate, identify the make and model of a car, and even notice that a cyclist isn't wearing a helmet. Returning a few rectangles with x and y coordinates feels like a simpler ask than any of that.
It turns out that it isn't, and the gap between what these models can describe and what they can locate is the core subject of this post.
What we're describing is object detection, a computer vision task where a model has to answer two questions simultaneously: "what is in this image?" and "where exactly is it?" The output is a set of bounding boxes (pixel-accurate rectangles drawn around each detected object) paired with class labels and confidence scores. The model isn't just classifying an image, it's locating every instance of every target class, at varying scales and positions, often overlapping, often partially occluded. It has to understand not just what objects are in the image, but where they sit relative to each other, spatial relationships that matter for everything from traffic monitoring to robotic navigation.
For decades this required purpose-built computer vision models trained on labeled datasets. Then VLMs arrived, and the question became obvious: can we skip the training entirely and just ask the model?
The tools
Object detection models
The standard approach to object detection uses architectures specifically designed for spatial localization.
YOLO (You Only Look Once) is a family of single-stage detectors that prioritize speed. First introduced in 2015, the architecture processes the entire image in a single forward pass, predicting bounding boxes and class probabilities simultaneously. This makes YOLO fast enough for real-time inference, often under 100ms per frame on modern hardware, including mobile devices. The current generation (YOLO26, by Ultralytics) runs comfortably on smartphones via CoreML or TFLite conversion.
DETR (Detection Transformer), developed by Meta, takes a different approach. It combines a CNN backbone with a transformer encoder-decoder and treats detection as a set prediction problem, eliminating anchor boxes and non-maximum suppression post-processing entirely. Variants like RT-DETR and RF-DETR have closed the speed gap with YOLO while often achieving higher accuracy on complex scenes.
Both architectures share a key property: their output heads are trained to regress bounding box coordinates directly from feature maps that preserve spatial information through the network. Localization isn't a side effect; it's the training objective.
Vision language models
You've heard of LLMs. ChatGPT, Claude, Grok, Gemini have become daily tools we depend on for work, performing exceptionally well at text-based tasks.
VLMs extend this capability to images. They combine a vision encoder (typically a ViT, or vision transformer) with a language model. The vision encoder converts an image into a sequence of token embeddings, and the language model reasons over those tokens to generate text. The input is an image plus a prompt, and the output is always text: descriptions, answers, classifications, structured data.
You've already seen what they can do. Describe an image in detail. Generate one from a text prompt. Produce video from a sentence. Read text in photos. Answer open-ended questions about visual content. Asking a model to locate objects in a photo feels like a small step from there.
I was tempted to think VLMs solve object detection the same way LLMs solved text generation, by making a hard problem feel like a conversation. But the gap between describing what's in an image and producing precise coordinates for where it is turns out to be fundamental, not incremental.
Visual question answering: where VLMs shine
VLMs are genuinely strong at tasks that require understanding rather than measurement. Given an image, they can classify scenes, read and interpret text, identify products by brand, answer questions about spatial relationships in natural language ("is the motorcycle behind the bus?"), and reason about image content in ways that detection models have no mechanism for.
A VLM can look at a construction site sign and read the project name, contractor details, permit number, and date, even when the image is blurry enough that contextual reasoning helps disambiguate characters. A detection model can draw a box around the sign. An OCR engine can extract the raw text. But neither can tell you whether the permit has expired or if the safety rating looks concerning, which is exactly where VLMs fill the gap.
The question is whether that semantic intelligence extends to precise spatial localization. Both the research and our own experiments suggest it doesn't.
The results
What the benchmarks show
Tenyks ran 200 API requests asking GPT-4 to return (x,y) coordinates for objects in images. Only five returned accurate coordinates, while Claude 3.5 Sonnet (via its vision API) refused to return coordinates or bounding boxes altogether. Roboflow independently confirmed the same with GPT-4V, calling the coordinates "not strong enough for production use cases."
Academic benchmarks paint a similar picture:
- ViewSpatial-Bench (2025, 5700+ QA pairs): GPT-4o scored 34.98% on spatial localization. Gemini 2.0 Flash scored 32.56%. Random chance was 26.33%. The best proprietary models barely beat guessing.
- GEOBench-VLM (ICCV 2025, 10000+ instructions): the best VLM, LLaVA-OneVision, achieved 41.7% accuracy on geospatial tasks, roughly double random chance but still far below practical reliability.
- VP-Bench (nearly 39000 image-question pairs): GPT-4o's spatial perception measured at 57.83%, its weakest capability dimension.
The "How well does GPT-4o understand vision?" paper tested several leading VLMs on standard COCO tasks. Direct bounding box prediction underperformed across all models. The authors had to develop a prompt chaining method that subdivides images into grid cells and progressively narrows the search, just to get approximate results. Their conclusion: models perform semantic tasks notably better than geometric ones.
The pattern is consistent: VLMs handle classification, description, and OCR well. Spatial localization remains fundamentally weak.
What we found firsthand
We hit the same wall building an on-device computer vision feature that required bounding boxes around detected objects in street-level images.
Phase 1: direct prompting. We sent street scene images to Claude 4.5 Sonnet's vision API requesting bounding box coordinates in normalized percentage format. The model identified objects correctly, described vehicles, read license plates, and noted traffic signs, and returned confident-sounding coordinates that turned out to be completely wrong. Boxes landed on empty road instead of vehicles, showing no correlation with actual target positions.
Phase 2: edge rulers. We overlaid percentage rulers (0-100) along the top and left edges of each image and updated the prompt to reference them. Positions remained off by 20-40%.
Phase 3: dense grid overlay. We burned a full coordinate grid into the image with yellow lines every 2%, major gridlines labeled every 10%, corner markers at 0,0 and 100,100. The model could read the grid labels correctly but still could not place bounding boxes at the corresponding positions.
Phase 4: multiple VLMs. Same images and grids across Claude, GPT-4V, and Moondream (covering the dense 0.5B and 2B models, as well as the 3-preview MoE architecture, both INT4 quantized and full-precision MLX). Smaller models were worse, with Moondream frequently returning a single box around the entire image. Larger models described content better but made identical spatial errors. We also noticed significant prompt fragility with Moondream: minor rewording of the prompt would shift its output unpredictably, sometimes producing entirely different bounding boxes for the same image. This mirrors the high sensitivity reported by Qwen2.5-VL users, where grounding accuracy can swing wildly based on the prompt.
Phase 5: multi-pass cropping. We had the VLM identify regions at a high level first, then sent cropped sub-images for detailed analysis. Description quality improved per crop, but the localization problem remained because the first pass couldn't produce accurate regions to crop from.
We ran all of this through a local comparison tool, a drag-and-drop web interface backed by a Python proxy server routing to both Moondream Station (running locally on Apple Silicon via MLX) and Claude's API. Both returned JSON with bounding box coordinates drawn as colored overlays on a canvas. The failures were immediately and visually obvious.
Why this is architectural, not a prompting problem
VLM vision encoders convert pixel data into token embeddings optimized for semantic similarity. The image becomes a sequence of patch tokens that capture what's in each patch but lose precise positional relationships between them.
When a VLM generates "the object is at 30% from the left edge," it's predicting the next probable token in a language sequence. There is no internal coordinate system, so the token "30" gets generated because it's the most likely completion, not because the model computed a measurement.
Detection models work differently. Their output heads regress bounding box coordinates directly from feature maps that preserve spatial information throughout the network. The loss function penalizes coordinate error, so every weight update during training pushes toward more accurate boxes.
The solution
Composite pipelines
The most productive architecture for tasks that need both understanding and localization is a composite pipeline:
- Run a detection model to localize targets with bounding boxes.
- Crop detected regions from the original image.
- Pass crops to a VLM for classification, description, or reasoning.
The detector handles "where," the VLM handles "what" and "why," and each model does what its architecture is built for.
This is the pattern Tenyks arrived at after finding VLMs inadequate for spatial tasks: their pipeline uses YOLO-World for bounding boxes and SAM 2 for pixel-level masks. Adding a VLM as a third stage for semantic interpretation is a natural extension of the same principle.
Grounding-capable VLMs
Some architectures are trying to close the gap from the VLM side. Qwen2.5-VL introduced native bounding box output using absolute pixel coordinates, with training that includes grounding tasks. Qwen3-VL extends this to 3D grounding with advanced spatial perception. PaliGemma takes a similar approach, extending its tokenizer with specialized location tokens for bounding box output. Molmo achieves grounding differently, using plain-text coordinate representation rather than special tokens.
This is genuine architectural progress, but it's not yet production-reliable. Qwen2.5-VL's grounding accuracy swings from 15% to 82% depending on exact prompt phrasing. That kind of sensitivity doesn't exist with trained detectors.
Qwen's own blog post demonstrates this capability with a street scene full of motorcyclists, where the 72B model draws individual color-coded bounding boxes around each rider and classifies whether they're wearing a helmet.
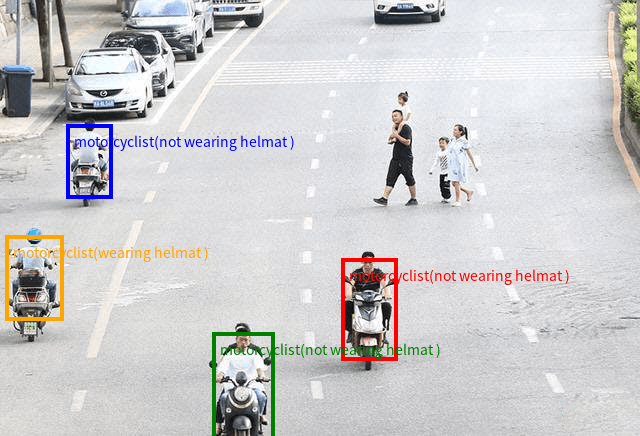
Qwen2.5-VL 72B on their selected demo image, from the official blog post. The model identifies each motorcyclist individually with color-coded bounding boxes and helmet classification.
We wanted to see how this holds up in practice, so we ran the same prompt format through Qwen2.5-VL 7B locally via Ollama and compared the results against YOLOv8n, the smallest and fastest variant in the YOLOv8 family, designed to run on edge devices, on the same images. On Qwen's own demo image, the 7B model produced correct bounding boxes for the motorcyclists, matching what the 72B model showed in the blog post.
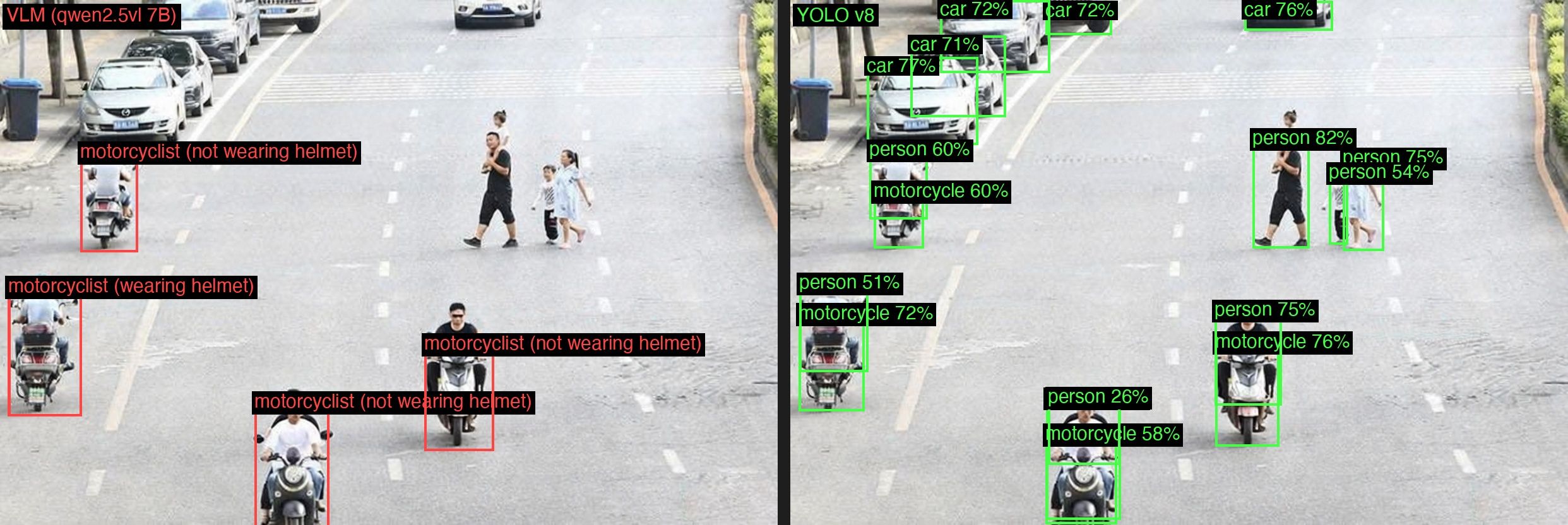
Left: Qwen2.5-VL 7B via Ollama. Right: YOLOv8n. On the demo image, both models identify the motorcyclists correctly.
You could argue that comparing a 7B parameter model to the 72B used in the blog post is unfair, but on the exact same image the 7B produced the same correct results, which suggests the image itself is what matters here. When we switched to a different image of motorcyclists, one pulled from the internet rather than selected for a demo, the result changed entirely. The 7B model returned a single bounding box covering the entire scene instead of identifying individual riders. YOLOv8n, meanwhile, continued to detect individual motorcycles and riders with the same consistency it showed on the first image.

Left: Qwen2.5-VL 7B on a new image draws one box around everything. Right: YOLOv8n detects individual motorcycles and riders consistently.
This is the kind of inconsistency that makes grounding VLMs difficult to rely on in production. The model can look impressive on curated examples and fall apart entirely on real-world inputs, and there is no reliable way to predict which images will trigger the failure mode without testing each one.
Where this stands today
As of early 2026:
- General-purpose VLMs (Claude, GPT-4o, Gemini) cannot reliably produce bounding box coordinates. Don't build production features that depend on this.
- Specialized grounding VLMs (Qwen2.5-VL, Qwen3-VL, PaliGemma 2) can produce coordinates with meaningful accuracy for some tasks, but remain prompt-sensitive and less reliable than trained detectors.
- Trained detection models (YOLO, RT-DETR, RF-DETR) remain the right tool for any task requiring consistent, pixel-accurate localization.
- Prompt engineering, grid overlays, and multi-pass strategies do not solve the fundamental architectural limitation. We tested this extensively.
- Composite pipelines (detector + VLM) outperform any single-model approach for tasks requiring both localization and understanding.
Test spatial accuracy with structured benchmarks early in your evaluation. The failure mode is invisible unless you measure it, because VLM outputs always sound precise regardless of whether they are.
What did we learn?
VLMs and object detection models are complementary, not interchangeable (at least not yet). Semantic understanding and spatial localization are separate capabilities that require separate tools. The research confirms what practitioners keep discovering independently, and building with that distinction in mind can save you significant time in experimentation.



